A brief history of workflow orchestration
This post was first published on Prefect’s blog and later discussed on Prefect Live.
For as long as we’ve been recording data with computers, we’ve been automating processes to handle that data. Basic orchestration concepts like “scheduler,” “job,” and “workflow,” have been reinterpreted and reimagined with each generation of technology. This is a short, selective, uncomprehensive history of the tools enabling, and concepts defining, workflow orchestration.
…”histories” should not be believed very seriously but considered as “FEEBLE GESTURES OFF” done long after the actors have departed the stage.
— Alan Kay, The Early History of Smalltalk
In the beginning, there was cron
Cron is a command line utility first introduced in Version 6 Unix, an early version of the operating system that many computers use today. The earliest reference to it appears in a man page in 1974, which described its function:
Cron executes commands at specified dates and times.
Cron is a simple scheduler. You can think of it as a recurring reminder, just like one that you might create on your to-do list. Using cron, you can set a schedule on a specific computer to execute a command on a recurring basis on that same computer. Cron takes very minimal input—five numbers separated by spaces, followed by the command to be executed. For example, the following command will print happy new year to the terminal of the computer that it’s running on, every year at midnight on January 1:
0 0 1 1 * echo happy new year
If you’re confused by how those numbers relate to the schedule, you’re not alone. Even engineers that use cron frequently need to use a cheatsheet to create a new schedule or understand an existing one.
Cron is still widely used today. While it isn’t very readable, its simple and universal—it’s included with nearly every computer. If all you need is to do is start a single script on a regular interval, cron gets the job done.
Then came the relational database
At about the same time that cron was released, another innovation was brewing, the relational database. It was a much more complex system that would transform computing and, accordingly, how recurring work was scheduled. There were several widely used relational databases, but the earliest and longest-lasting commercially successful database is Oracle. Oracle v2, the first commercially available version, was released in 1979. The next decade saw rapid uptake of Oracle and relational databases like it. These databases had basic scheduling features, similar to cron, through most of their early history.
In 1995, Oracle introduced job queues, described in its 7.2 release notes as:
a new feature… that enables you to schedule periodic execution of PL/SQL code.
If cron is a scheduler for a single reminder, then a job queue is the entire to do list, in which the order of the jobs on the list is known and can be changed. The Oracle7 administrator’s guide describes how jobs could be submitted, removed, changed, broken, or run, giving users a richer way to think about their jobs. Instead of simply creating a job the moment that it was supposed to start, DBMS_JOB kept a record of the next time each job would run, enabling engineers to see the order in which jobs would run before they started. This record also enabled engineers to monitor jobs through a simple SQL query as they executed. DBMS_JOB would even retry a job up to 15 times if it failed. If the job failed to successfully execute, it entered a “broken” state, but users could mark a job as not broken if they’d like. While DBMS_JOB was not the only tool of its kind, it’s broadly representative of the tools of its time.
While Oracle is still the most popular database in use today, DBMS_JOB has since been replaced by another package, DBMS_SCHEDULER, with similar capabilities. Most data storage and processing tools have something comparable. If all of your data, and all of the processing of that data, is in a single tool, that tool’s default scheduler might be the best tool for you.
The rise of data warehouses and data integration
Again, while one generation of tools was blossoming, the seeds of the next were being sown. Oracle and its competitors were wildly successful in enabling database adoption through specific applications, such as point of sale systems. Eventually, their customers found themselves with several disparate applications, each with its own database. Cron was a scheduler for a single computer, and DBMS_JOB was a scheduler for a single database, but as organizations started storing and processing data across multiple computers and databases, a new class of tools emerged. The practice of moving data from separate, often application-specific, databases to a data warehouse became known as data integration. Some niche communities, like geospatial, called it data fusion (it’s a shame that didn’t catch on - it sounds way cooler).
Each database has a specific way of organizing data called a schema. To copy data from the “source” application database to the data warehouse, often called the “target”, it needed to be translated from one schema to the other. Because both the source and target databases were slow and capacity-limited, that transformation needed to happen between them, in the data integration tool itself. So data integration tools extracted data from the source system, transformed it into the schema of the target, and loaded it into the warehouse. This extract, transform, load (ETL) pattern became so common that it was, and still is, nearly synonymous with any movement of data.
The first and most successful commercial data integration tool was Informatica. Founded in 1993, Informatica really started to take off in 1998 with the introduction of its PowerCenter product, which is still in use today. In Infoworld’s November 1999 issue, Maggie Biggs summarized PowerCenter 1.6 as:
an enterprise data integration hub that unites data warehouse, data mart, and decision support operations.
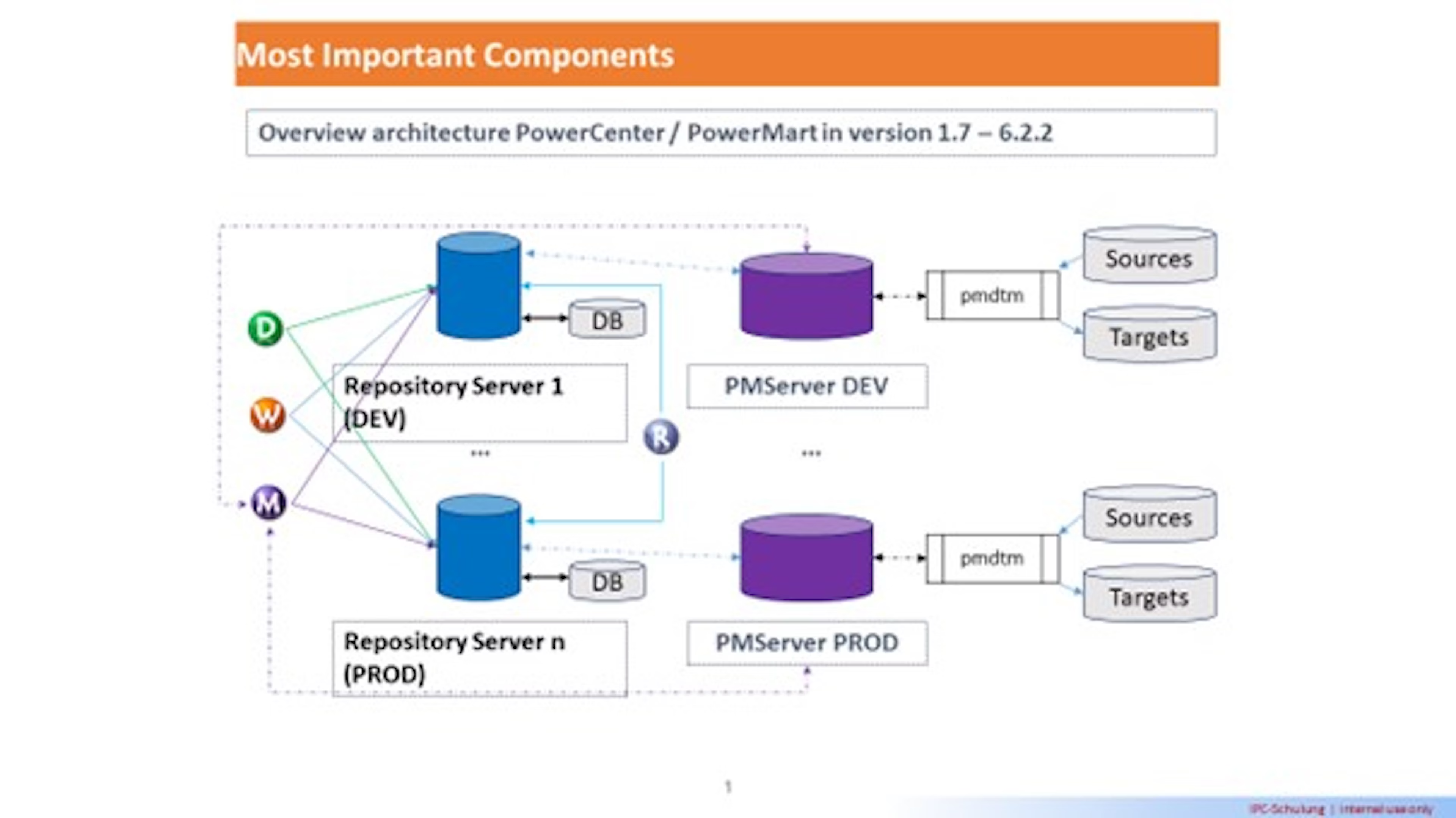
PowerCenter was one of the first tools designed entirely around managing runs of scheduled jobs. It recorded metadata about these jobs—when did which job run, how many records have been processed, and so on. It was also one of the first tools to introduce a concept of a “source” from which the data came, a “target” in which the data ended up and a “workflow” that united the two.

There are many such data integration tools today, all of which have a similar pattern shaped largely by moving data from one or more relational databases to a data warehouse in large enterprises. If that describes your company, you may already have a tool like Informatica in place.
The big data era
In the 2000’s, data warehouses were still capacity-limited, relatively slow, and expensive. In 2006, as they continued to mature, Google open-sourced Hadoop, which popularized a new way of storing and processing data. Instead of storing all of the data in a single warehouse on a single computer, data was instead stored across many computers in separate files, often with less structure. Circa 2011, This pattern became known as a data lake. Data lakes were simpler and cheaper way to store data, but processing it was much more complex.
So, as had been done many times before, a new generation of engineers built a new set of tools: workflow orchestrators. Workflow orchestrators were intended to work with Hadoop and tools like it. Accordingly, they were inspired by its concepts. Hadoop’s primary data processing components, MapReduce and YARN, organized data processing as a “job” that must be a “DAG” — a directed acyclic graph — of “tasks.”
Oozie was open sourced by Yahoo in 2010. It was one of the first of this generation and the most tightly coupled to Hadoop. O’Reilly’s Apache Oozie: The Workflow Scheduler for Hadoop described it as:
an orchestration system for Hadoop jobs.
Luigi was open sourced by Spotify in 2012. Their blog post described it as:
a Python module that helps you build complex pipelines of batch jobs, handle dependency resolution, and create visualizations to help manage multiple workflows. Luigi comes with Hadoop support built in.
Azkaban was open sourced by LinkedIn in 2014. Their web page described it as:
a batch workflow job scheduler… to run Hadoop jobs. Azkaban resolves the ordering through job dependencies and provides an easy-to-use web user interface to maintain and track your workflows.
Airflow was open sourced by Airbnb in 2015. It has been, by far, the most popular of this generation of tools, and is still in wide use today.
In addition to the technological advances of workflow orchestrators, there was a major change in adoption patterns. While cron was open source, subsequent generations of tools were exclusively proprietary. Tools like Informatica were designed to be purchased by the management of back office IT teams at Fortune 500 companies. They were expensive and hard to replace once deployed, creating vendor lock in. Workflow orchestrators, by contrast, were designed for engineers, by engineers at some of the greatest tech companies of the time. They were free and open source. This gave users the freedom to modify and maintain the tools themselves.
Slouching towards the Modern Data Stack
You guessed it. Just as Hadoop-era tools were becoming popular, the next wave - or rather, several waves - was forming.
In late 2011 and early 2012, right about the time that Katy Perry’s “Firework” was dominating the music charts, cloud data warehouses came on the scene:
- Google Cloud Platform released BigQuery in General Availability
- Snowflake was founded
- Amazon Web Services announced Amazon Redshift
These cloud data warehouses, especially Redshift in the early years, were way cheaper and faster than existing, on-premise data warehouses. In short order, people started using data warehouses in new ways. For example, since data warehouses could now transform data easily, data no longer needed to be transformed before being loaded into the data warehouse. Extract transform, load (ETL) became extract, load, transform (ELT).
In late 2013 and early 2014, while everyone was jamming to the positive vibes of Pharrell’s “Happy,” some new technologies for processing distributed data emerged:
- Spark 1.0 was released, and Databricks, the company commercializing it, was founded
- Kafka 0.80 was released, and Confluent, the company commercializing it, was founded
These tools exposed more familiar interfaces, like SQL, on data lakes, making them more accessible and usable. They also increased speed and performance so much that they enabled near real-time processing that became known as streaming.
These events set off a series of architectural shifts that are still playing out today. Andreessen Horowitz’s Emerging Architectures for Modern Data Infrastructure captured many of them in a single slide:

Over the past five years or so, a confluence of venture capital and open source code has given rise to a Cambrian explosion of data management tools that we all somehow started calling the Modern Data Stack.
When each generation of technology came along, it didn’t fully, or even mostly, replace the previous generation. Instead, a new tech “stack” was built alongside existing ones. Today, many organizations have simple scripts scheduled by cron and in-database jobs and data integration workflows and DAGs mapped over distributed file storage, and stream processing and web services with REST APIs. Modern workflow orchestration tools need to work with all these systems.
Like the many generations of builders that have come before us, we too determined that a change in the technology demanded a change in the nature of workflows themselves. Concepts that were useful in an earlier generation, like DAGs, are constraining now. Modern workflows are dynamic, multi-modal, asynchronous, and fast.