How we talk about data
The language of technology is notoriously ambiguous, ridden with buzzwords and jargon. Specific technologies and general technical concepts rise and fall in relevance and perceived value so frequently that the phenomenon has its own moniker, the hype cycle. Over the past ten years, new terms have risen in popularity to describe data management activities that have been going on for decades. Some of the change in language has been motivated by marketers trying to generate buzz, but it has also been driven by genuine advancements in the underlying technologies and a need to distinguish between older and newer ways of doing things.
Sometime around 2010, a confluence of cheaper, faster, and distributed storage and computation gave rise to one of the most loaded buzzwords of all time: Big Data. There has been no shortage of attempts to define Big Data. It is best thought of as a mega-trend encompassing many constituent trends shaping the activities involved in deriving value from data. This table breaks down some of these activities and the associated pre and post big data vocabulary.
| Activity | Pre Big Data | Big Data |
|---|---|---|
| Storage | Data Warehouse | Data Lake |
| Transport | Extract, Transform, Load (ETL) | Data Pipeline |
| Descriptive Analysis | Business Intelligence | Business Analytics |
| Statistical Analysis | Data Mining | Data Science |
The pre Big Data terms are most commonly used to describe an approach for a world of more expensive, slower, and centralized data storage and computation. The Big Data terms are broader. They reflect the variety of approaches that have been enabled as the age of Big Data has come about. This is more analogy than dichotomy - the pre Big Data approaches have not replaced the Big Data approaches, but instead complemented or encompassed by them. Let’s explore the trends in each term’s use (measured by Google searches) and the technology shifts that underpin each set of terms.
Data Warehouse vs Data Lake
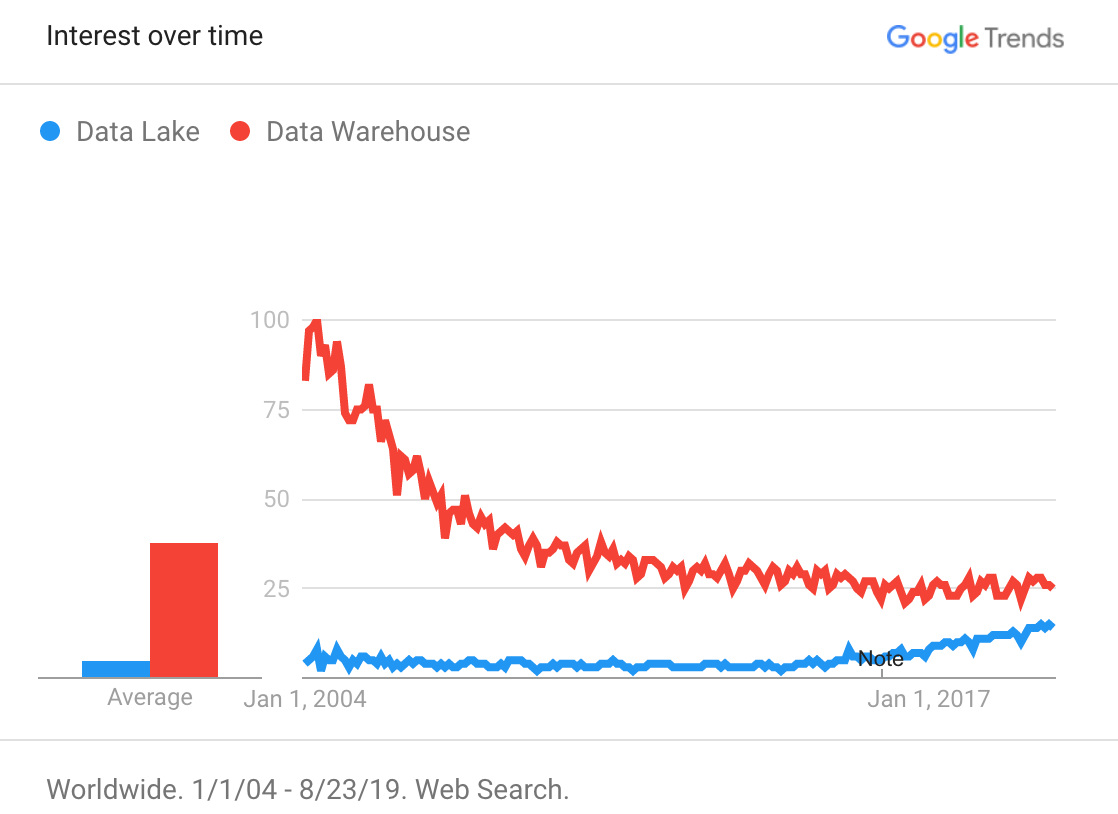
“Data Warehouse” searches have declined continuously, while “Data Lake” searches have increased slowly but steadily over the past five years
Data warehouse typically denotes an architecture that stores structured data from several operational, transactional source systems that has been aggregated, denormalized, or otherwise reshaped to support queries for predefined business questions. When gigabytes and CPU cycles are expensive, it makes sense to be deliberate about what data is kept and how it will be accessed.
Data lake typically denotes an architecture that stores structured, semi-structured, or unstructured data from many source systems in its raw form to support ad hoc business questions. When gigabytes and CPU cycles are cheap, why not keep all the data in case there is a need for it later?
The development of data lakes to complement existing data warehouses has driven changes in the upstream architecture of data transport and integration. It has also enabled changes to the downstream consumers of the data.
Extract, Transform, Load (ETL) vs Data Pipeline
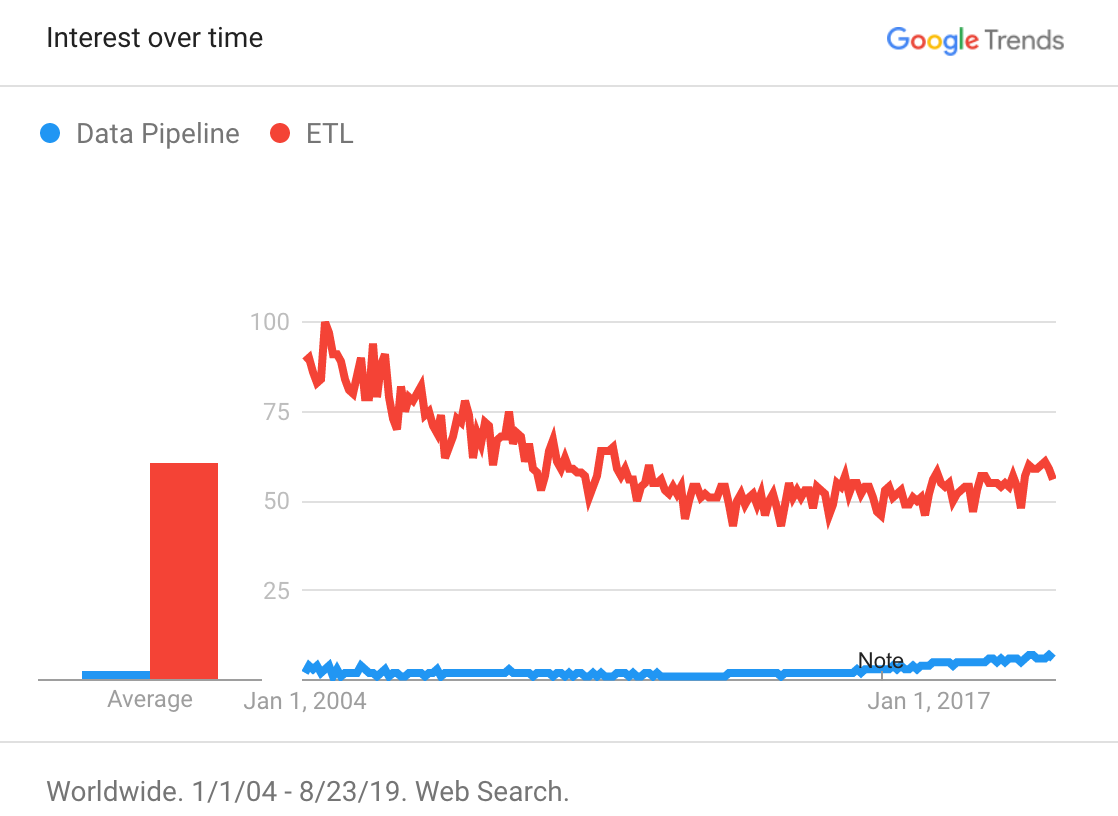
While “ETL” searches are still common, searches for “Data Pipelines” are becoming more popular
Extract, Transform, Load (ETL) is a catch-all term for moving data from one system to another. It implies a specific order in which the E, T, and L activities take place. Commonly, the source system is an operational, transactional system and the target system is a data warehouse. ETL is the only viable approach because the data must be reshaped to fit the predefined schema before being loaded into the data warehouse.
Data pipeline is a more general term that does not imply a specific order in which the E, T, and L activities take place, as ETL does. Data pipelines may include ELT pipelines or pipelines that simply extract data from one system and load it into another, without transformation. The latter is increasingly common as data lakes become more prevalent.
Business Intelligence vs Business Analytics

“Business Intelligence” searches are declining and were overtaken by “Business Analytics” in early 2018
Traditional business intelligence tools, like Business Objects, sit on top of data warehouses. They are used by developers to create reports and dashboards for consumption by Business Analysts. With the advent of self-service BI tools, like Tableau, the line between creator and consumer has blurred, but the goals are the same. The goal of Business Analysts is usually to understand what happened and why. Accordingly, business intelligence tools are best suited to derive descriptive statistics and produce reports. Business Analysts are data literate but not commonly well versed in statistics or machine learning.
Data Mining vs Data Science
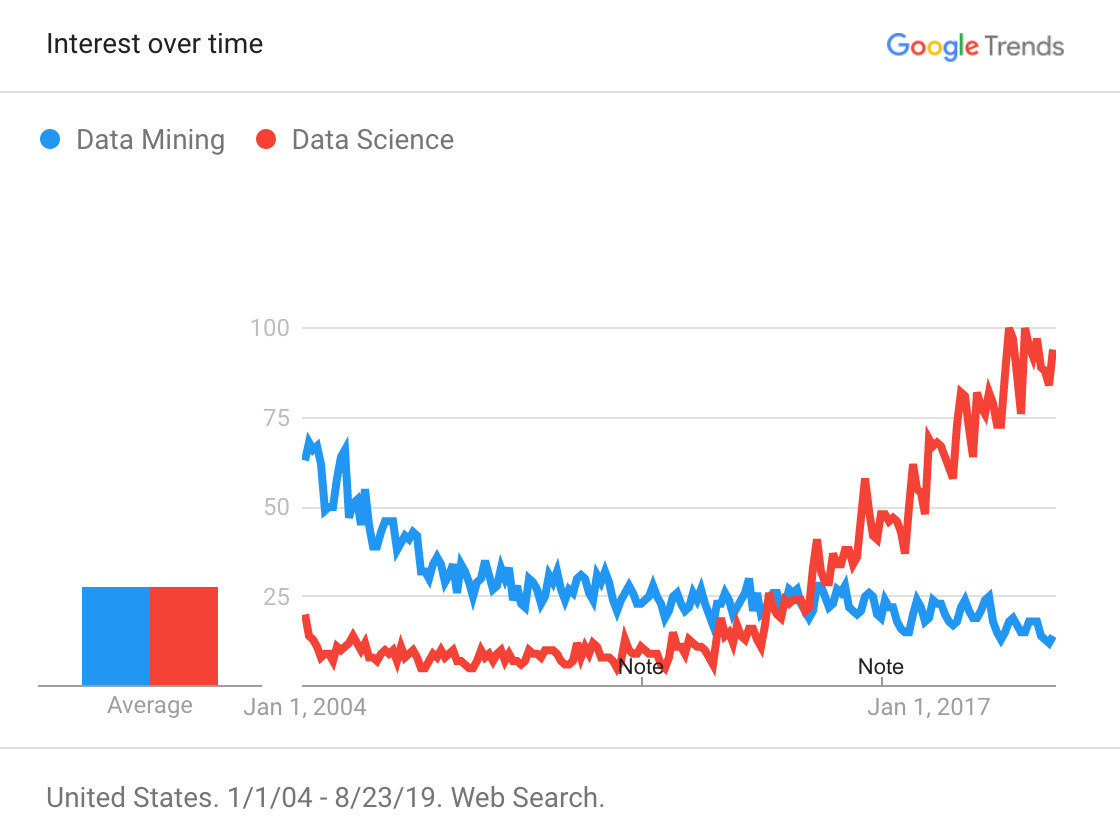
“Data Mining” searches have been on a slow and steady decline, meanwhile “Data Science” searches have taken off in the past five years
Of all of the terms we’ve compared, these are the most ambiguous. Traditional data mining tools, like SAS, have a graphical user interface and are used by statisticians, who are competent with statistics, but perhaps not in programming. The rise of Data Science has a corresponding rise in a new title - Data Scientist. Data Scientists tend to have deeper programming skills and tend to use open source programming languages like R or the Pydata ecosystem. Data Scientists use these tools to create “data products”, like Spotify’s Discover Weekly.
Language Reflects Changes in Data Management Concepts
Of course, language can be imprecise. These terms are often used interchangeably. Importantly, the advancements in storage and computation have enabled improvements to the pre Big Data approaches as well. The distinction that these terms imply is not so much about what is being done as it is how it is being done. The pre Big Data approaches are still dominant in some cases, but the post Big Data approaches are becoming increasingly important.